PS. I did a rough video on this.
You should probably visit the ‘Tutor’ (data capture application) to get an idea of what I’m talking about before reading on.
This mini-project is a tangent to the ELFQuake project proper, to help familiarize myself with machine learning techniques & tools.
After this occurred to me last week, I’ve made some progress in implementation. But first some background.
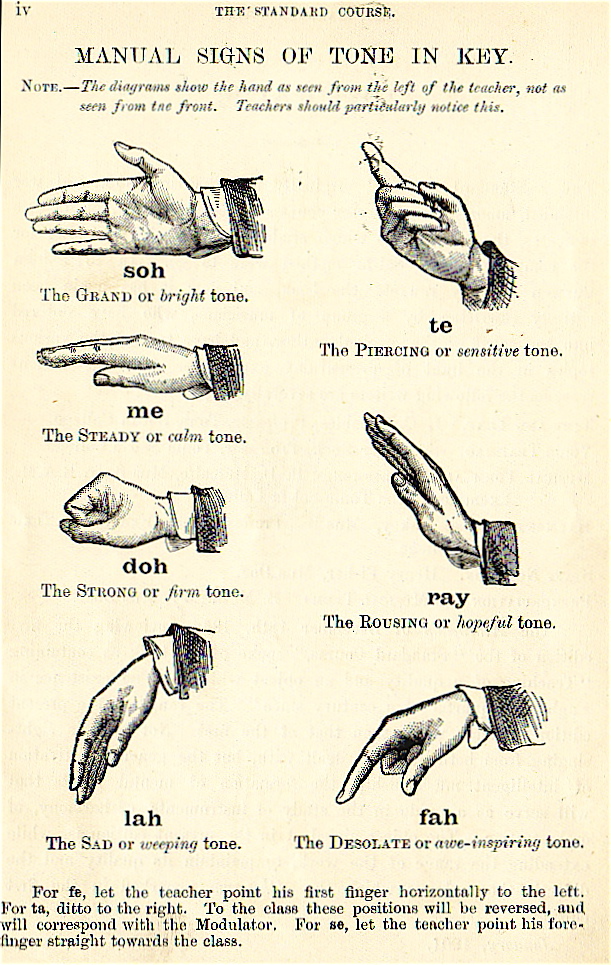
Solfège Hand Signs
Solfège, Curwen, or Kodaly hands signs are a system of hand symbols representing the different pitches in a tonal scale. They’re used to provide a physical association of a pitch system to help connect inner hearing and reading of pitches with musical performance.
from What Is The Purpose Of Solfege Hand Signs?
In their basic form, these are 7 hand signals that are associated with the notes of Tonic sol-fa notation : do, re, mi, fa, sol, la, ti
They made an appearance in the wonderful 1977 film Close Encounters of the Third Kind :
For the musically inclined among you, only having 7 tones may seem a bit limited – even Close Encounter’s tune uses the do at an octave. I believe Kodaly’s extension of Curwen’s system allows a greater range by holding the sign higher or lower (I think – need to google some more). Also the semitones in between are covered. The diagram above mentions fe, ta, and se, whatever they might be. But for now 7 tones feels like plenty.
The Aim
To build a system capable of recognizing Solfège hand signals and playing appropriate tones.
This has been done before – MiLa: An Audiovisual Instrument for Learning the Curwen Hand Signs – but that system used specialized motion capture hardware. Here the plan is to use a regular webcam.
Right now I’m only thinking of getting to a proof of concept, though given that I’ve got an ESP32-Cam module sitting on my shelf, and TensorFlow Lite Micro is supported, there’s potential for embedded fun further down the line.
The Plan
- Acquire a lot of images of the hand signals (with associated labels)
- Train a machine learning system with that data
- Use the trained model to take hand signal images from a webcam and generate the corresponding tones, in real time
Let me unwrap that, starting with 2.
MNIST
The MNIST database of handwritten digits is commonly used as a benchmark for testing pattern recognition/machine learning algorithms. It comprises a total of 70,000 images with associated labels (0-9), which looks something like this –

Typically you take the training set of 60,000 images, fire them (and their labels) at your learning system for as long as it takes. Then you use the test set of 10,000 images (and labels) to evaluate how good your system is at recognising previously unseen images.
This is isomorphic to the core of what is required to recognize hand signals.
There are a lot of systems coded up to work on MNIST. It’s hard not to see a competitive element where different algorithms are proposed that push the accuracy up a little bit further. Wikipedia lists a bunch of classifiers, with error rate ranging from 7.6% (Pairwise linear classifier) to 0.17% (Committee of 20 CNNS with Squeeze-and-Excitation Networks [?!]).
Where the code is available, it’s typically set up to allow reproduction of the results. You point say train.py at the MNIST image and label training set files, wait potentially a very long time, then point test.py at the test set files, then hopefully soon after some numbers pop out giving the accuracy etc.
While the MNIST database is ubiquitous, various limitations have been pointed out. The elephant in the room is that the fact that a particular system does exceedingly well on MNIST doesn’t mean it’ll be good for any other kind of images. This and other issues were the motivation for Fashion-MNIST, a database of more complex images.
I have absolutely no idea what kind of system topology will work well with the hand signals, they are qualitatively a lot different than handwritten digits. But, if I format my dataset as a drop-in replacement for MNIST, I can pick a wide variety of setups off the shelf and try them out, with no extra coding required (this is also the approach taken with Fashion-MNIST). Parameter tweaking will no doubt be needed, but simple trial & error should cover enough bases.
The MNIST format does look rather arcane, but it shouldn’t take me too long to figure a script to compose the data this way.
Back to the Plan part 1.
Data Acquisition
MNIST has 70,000 images. Even if I could capture one a second, this would still take about 20 hours. Noooo..!
But I’m only aiming for a proof of concept, I will consider that achieved with something like a 90% success rate. Almost ever paper you see featuring machine learning will have a chart somewhere with a curve that starts steep and quickly levels off, becoming virtually flat a little way below some desired goal.
I think it’s reasonable to assume most of the systems that can operate on MNIST-like data will have this characteristic, with size of training dataset on the horizontal axis and accuracy on the vertical.
How many sample images will be needed to get to 90%? Clearly it will depend on the algorithms, but in the general case I have no idea. Lots.
So I need to be able to capture images quickly.
After a bit of futile play trying to get a Python GUI app going I gave up (curse you Wayland!), decided to try Javascript in the browser instead. Which, after what experts might consider excessive time on StackOverflow and not enough on MDN API docs,
I got running as a single-page application.
The capture of images from the webcam was straightforward via a <video> element (although there is an outstanding issue in that I couldn’t get the camera light to go off).
Processing, via <canvas> elements turned out to be a lot more convoluted than I expected, I didn’t find that intuitive at all. ‘hidden‘ is the keyword.
Similarly, it took me a good while to figure out a quick way of saving the final image to file (by addressing a hidden <a> element programmatically).
I started with mouse input on <button> elements but soon realised (as any fule kno) that for speed it had to be the keyboard. But that and the rest was pretty straightforward. Generating the tones was trivial, although my code might not be as considerate to the host as it could be.
A huge advantage of implementing this in a browser (aside from being able to get it to work) is the potential for crowdsourced data acquisition. I’ll tweet this!
It was pretty much an afterthought to try this on a mobile device. When I first tried it on my (Android) phone, Capture didn’t work. It is quite possible I had the camera open elsewhere, but I’m still confused why I could see the video stream. Today I showed it to Marinella on her phone, expecting Capture to fail there too. It worked! I just tried again on mine (making sure camera was off), it worked there too!
Even if it does basically work on mobile, there’s still a snag. Ok, from the desktop I can ask people to zip up a bunch of images and mail them to me or whatever. Doing things like that on a mobile device is a nightmare.
If anyone says their willing to capture a bunch of images, but it’ll have to be on mobile, I’m sure I can set something up to quickly post individual images from the application up to a server.
Onto Plan part 3.
Runtime Application
You make a hand signal to a camera, which is periodically taking snapshots. If a snapshot is recognised with reasonable certainty as being of a hand signal, the corresponding tone is played.
Implementation is very much To Be Decided, I’ve got all the data conversion & model play to do first.
Because the ML code will be built with Python, my original thought was to go with this for an application, like a little desktop GUI. I’ve since gone off this idea (blast your eyes, Wayland!). I sometimes forget that I’m a Web person.
So provisionally I’m thinking I’ll set it up as a service over HTTP. Aaron’s web.py is a fun thing I’ve not played with for a long time.